前言
图是一种常见的数据结构,其反映数据所对应元素之间的几何关系和拓扑关系。图数据库是一种非关系型数据库。它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
cypher是用于neo4j的查询语言。
本文仅对工作中的使用点进行总结,后期会继续更新。可能有些地方有些偏颇。请见谅。
⚠️⚠️⚠️社区版免费,企业版收费。并且企业版费用不低。价格参考表。
正文
CRUD
增
节点:
create (n:xxx{att:value}) //单节点
create (n),(m);//多节点,注意创建多节点的时候自定义变量(前面的n、m是用于捕获结果)不能重复,即create (n),(n);是会报错的。
create (n:label1:lable2:label3) //带标签的节点。标签可以用来创建索引,从而有助于优化对节点的查询。标签的命名规则:数字、字母、下划线,首字母不能是数字。
create (n:xxx{att1:value1})//创建带属性的节点。
关系:
create:
create (n1:xx)-[r:xxx]->(n2:x) //创建单关系
create (n1:xx)-[r:xxx]->(n2:x),(n11:xx)-[r1:xxx]->(n22:x)//创建多关系
create ()-[r:xx{att:value}]-()//创建带属性的关系
create k = (n1)-[r1:friend{location:’China’}]->(n2) return k //创建具有节点和联系的全路径
create unique:
match (n)-[r]-(n1)
where n.id = xx
create unique (n)-[r1]-(n2:{name:’want’})
return n,r,n1,n2 //创建唯一的节点和联系。create unique语句,这个语句放在match和create这里,对于match上的节点和关系会新建缺省元素。
merge:
megre (n:xxx{att:value}) Merge好似if-else语句,基本逻辑是先检测merge后面的条件,看看有没有匹配的返回值,如果有则执行on merge分支,如果没有则走on create。
create unique与merge区别:Create Unique部分匹配就可以,而Merge则只有整个模式都匹配才创建,否则什么也不做。
改
更新属性值:<br
match (n:xxx{att:value}) set n.att = newValue return n
除了create 和 delete 以外其他语句都必须要以return结尾
更新标签:
match (n:lable1:label2) set n:newLabel1:newLabel2 return n;
更改关系:
先删除旧的关系,再建立新的关系。
删
delete:
不建议使用match (n) delete n (强保护机制,必要要先删除关系再删除节点)
而是使用:match (n) detach delete n (弱保护机制)
remove:专门删除属性、标签
match (n:xxx{att:value}) remove n.att return n;//删除节点的某一个属性
match (n) remove n:label//删除某一个标签,注意如果标签有约束,需要先删除约束:DROP CONSTRAINT ON (p:lable) ASSERT p.id IS UNIQUE
match (n) where n.id = xxx set n.att = null;//将某个属性设置为null也是删除属性的一种方法。
查
match(查询)...where:
在match之前可以进行定位用以加快查询速度。
常见聚合操作:count、distinct、max、min…
标签限定
在version2开始引入对标签的限定。暂时只有unique能用。
1
2
create constraint on (n:MALE) assert n.name is unique;
可以确保name属性是唯一的。
模式与模式匹配
- 节点模式:
使用括号进行描述 - 标签模式:
增加标签限定,多个标签起到交集作用 - 关系模式
match (a:A)-[b:relations]->(c:C) return a,b,c
首先会搜寻两个标签节点,再去这些节点中寻找符合relations关系。
双向就不要剪头:match (a:A)-[b:relations]-(c:C) return a,b,c - 属性模式
属性匹配使用的是花括号和键值对,其间使用逗号分隔。 - where:
where不能单独使用,只能用在match、optionalmatch、start、with的后面,用以进一步过滤模式的数据。
where从句中使用模式: 5.1. 对于一个集合,如果是空集,那么代表false,非空代表true。可以使用in关键字来进一步限定。(这种做法在数据量大的时候会导致查询速度非常慢,在match之前进行定位可以解决)。=~ 不等于。点号和[]是相等,但是用法讲究。对于[],其间必须是常量。
5.2. 使用exists()函数进行属性校验。
1 2 3
match (x) where exists(x.age) return x.name
5.3. 字符串匹配:starts with、ends with、contains
1 2 3
match (x) where x.name starts with "B" return x.name
5.4. 其他从句:
5.4.1. order排序(默认是升序,支持混排)
5.4.2. limit限制返回数,skip跳过前多少个数据。1 2 3
match (n) return n order by n.age skip 3 limit 3
5.5. with从句:with的作用就是连接多个查询结果,有点类似linux中的管道的意思。
5.6. union、union all:
union的用法与SQL一样,用于连接两个Match,返回结果中剔除了重复记录。但union all功能一样,但不剔除重复记录。APOC
APOC是Neo4j 3.3版本推出时正式推荐的一个Java存储过程包,里面包含丰富的函数和过程,作为对Cypher所不能提供的复杂图算法和数据操作功能的补充,APOC还具有使用灵活、高性能等优势。传送门。
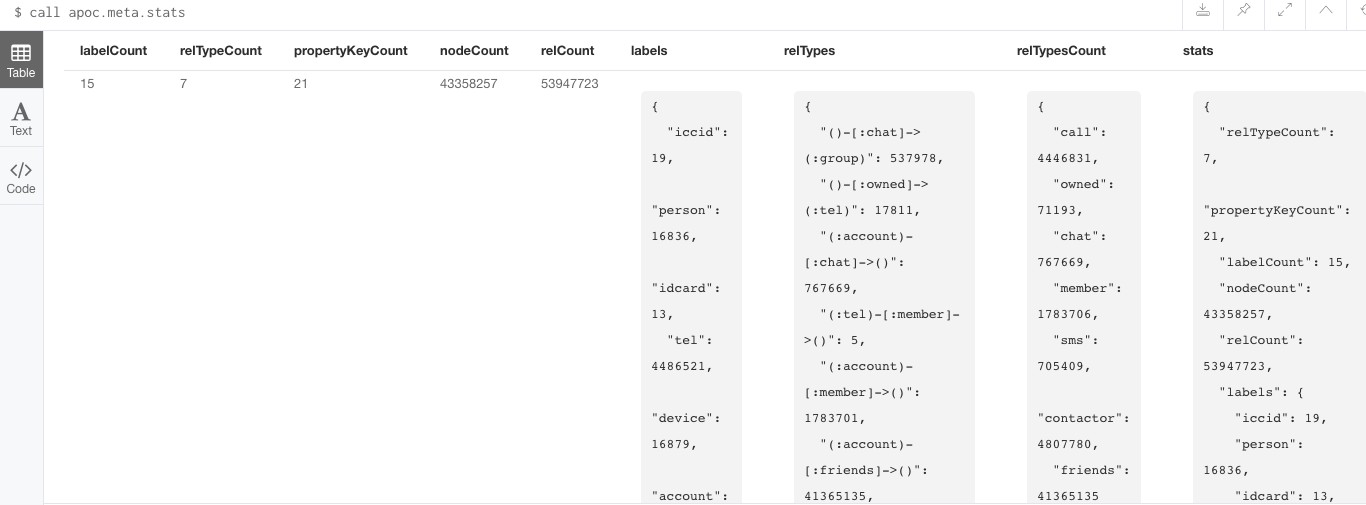
- 内置函数 包含 字符串处理、时间戳、统计、日期、科学计数法等。 call apoc.meta.stats返回当前数据库的一些统计信息。 call apoc.meta.graph返回当前数据库的一些统计信息。 *call apoc.text. **
- 图论算法
其中有一个内置函数:apoc.meta.stats 它可以返回当前数据库的一些统计信息。
最短路径
说到图就绕不开图算法中的寻路算法。其中最为常用的就是最短路算法。neo4J自身提供了一个最短路的函数–shortestPath。
1
2
3
4
5
6
7
8
9
MATCH (n:person) where n.id IN (某种条件)
WITH collect(n) as nodes
UNWIND nodes as n
UNWIND nodes as m
WITH * WHERE id(n) < id(m)
MATCH path = shortestPath( (n)-[*..%d]-(m) )
RETURN path
附上:两个节点之间的最短路
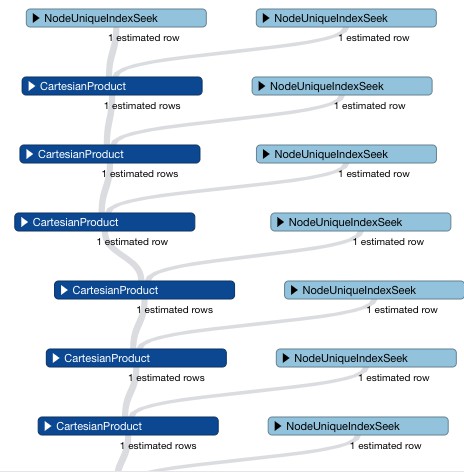
match (n:account{id:'wxid_zfgv7wjpdajk11'}),(m:account{id:'wxid_htl2hw3r0fbt12'}) match p=shortestPath((n)-[*]-(m)) return p
解释:
1、match满足某种条件的节点。
2、将所有满足条件的节点放到一个列表中命名为nodes。
3、使用两个unwind再次将结点列表打散到行,两个unwind的结点是以笛卡尔积的方式返回的,所以这里是两两的任意组合,甚至两个结点相同的组合,实际上我们这里求最短路径1到2和2到1肯定是一样的,所以用id(source) < id(target)来去除一半。
4、最后是shortestPath函数,里面的source,target就是前面的组合。
查询优化
Neo4J在version2引入索引策略,可以对标签进行限制和索引。Neo4J的索引和关系型数据库的定义相类似。主要用于提升节点寻找的性能。对于任何已有数据结构的更改操作,索引自动更新。如果出了错而导致索引处于无效状态,便需要差错并重新生成它们。Cypher查询会自动使用索引,Cypher有一个查询计划器和查询优化器,可以对查询进行评估并尝试尽全力依据选索引择最短执行时间。
查看索引:
1、:schema(查看索引和约束)
2、CALL db.indexes YIELD description, label, properties;
创建索引:
create index on :lable(attName)
删除索引:
delete index on :label(attName)
索引使用:
默认是自动使用的。 一旦索引建立,随后但凡在where从句中出现具有索引的属性时,不论是简单的等值比较还是其他条件,索引的使用都是自动的。
但是也可以显式的指定索引的使用方式–using从句,using从句中是可以在单一查询中提供多个索引项来给cypher查询优化器提供索引提示。
附:约束
查看约束情况:
CALL db.constraints
建约束
CREATE CONSTRAINT ON (movie:Movie) ASSERT movie.title IS UNIQUE
注意:Adding the unique constraint will implicitly add an index on that property. If the constraint is dropped, but the index is still needed, the index will have to be created explicitly.–截取至官方文档。唯一约束会自动创建索引。删除约束后需手动创建该索引。
删约束:
DROP CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
1
2
3
4
match (n:label)<br>
using index n:label(attName)<br>
where n.attName = attValue<br>
return n<br>
使用scan给Cypher Query Planner先扫描所有标签然后再执行后续的过滤,这种做法的结果意味着优秀的性能,毕竟使用标签本身可以不必考虑那些不必要的数据。这种做法的性能是较好的。
1
2
3
4
match (n:label)<br>
using scan n:label<br>
where n.attName = attValue<br>
return n<br>
理解查询计划:
Neo4j使用的都是基于成本的优化器(Cost Based Optimizer,CBO),用于制订精确的执行过程。可以采用如下两种不同的方式了解其内部的工作机制:
EXPLAIN:是解释机制,加入该关键字的Cypher语句可以预览执行的过程但并不实际执行,所以也不会产生任何结果。
PROFILE:则是画像机制,查询中使用该关键字,不仅能够看到执行计划的详细内容,也可以看到查询的执行结果。
优化举例
优化前的cql:
1
2
3
4
5
6
7
8
explain
MATCH (n) where n.id IN ['binbin287644658']
WITH collect(n) as nodes
UNWIND nodes as n
UNWIND nodes as m
WITH * WHERE id(n) < id(m)
MATCH path = (n)--(m)
RETURN path
查询速度非常慢,因为节点走了全部节点扫描。原因是match (n)中并没有对标签进行限制。所以我们建立的索引是没有用处的。
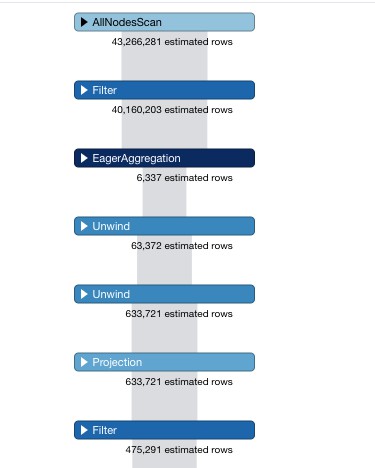 优化后的cql,主要就是使用字符串拼接的方式将具体的节点进行定位。
优化后的cql,主要就是使用字符串拼接的方式将具体的节点进行定位。
1
2
3
4
5
6
7
explain
MATCH (n1:account {id:'wxid_hrm0cfv931j422'}),(n2:account {id:'binbin287644658'}),(n3:person {id:'320682198612083600'}),(n4:tel {id:'15258868649'}),(n5:device {id:'356996069532389'}),(n6:account {id:'a27563427'}),(n7:account {id:'wxid_q409jxhxvd0q12'}),(n8:account {id:'1004250324'}),(n9:tel {id:'666697734343'}),(n10:account {id:'wxid_xdbjmo94qzlm80'}),(n11:account {id:'lcg476634048'}),(n12:account {id:'ann_48'}),(n13:account {id:'liuxin601248'})WITH [n1,n2,n3,n4,n5,n6,n7,n8,n9,n10,n11,n12,n13] as nodes
UNWIND nodes as n
UNWIND nodes as m
WITH * WHERE id(n) < id(m)
MATCH path = (n)--(m)
RETURN path