MongoDB 是非关系型数据库的典型。官网对它的描述是:基于分布式文件存储的数据库,其拥有高性能、可扩展、易部署、易使用,存储数据非常方便等优势。
本文旨在列举实际工作中常用到的一些知识点,以及其相关的扩展知识。系统的学习请参阅官方文档。
优势:
1、文档型NoSQL数据库。数据以文档的形式在MongoDB中保存,文档实际就是JSON字符串,JSON字符串容易阅读,且主流的计算机语言对其有很好的支持。
2、基于文档的灵活的数据模式。相比MySQL,无需使用DDL对表结构进行修改。
3、强大的索引能力。支持一级、二级、TTL索引和地理位置索引等。
4、强大的扩展能力。分片机制用于实现业务的水平扩展,每个分片只保留业务的部分数据,并且支持副本集,确保分片上的数据的高可用性。
适用的业务场景
1、敏捷迭代的业务,需求变动频繁,数据模型无法确定。
2、存储的数据格式灵活,不固定 ,或属于半结构化数据。
3、对数据高可用性有高要求。
4、需要大量的地理位置查询、文本查询。
5、无需跨文档或跨表的事物及复杂的join查询支持。(4.0之后支持多文档事物,多文档事物可以理解为关系型数据库的多行事物。)
内容
Schema定义实践
针对表结构定义这件事而言,重要的应该是仔细。扣原型上的每一个地方,当然出于一些功能上的实现,我们也需要再补充一些字段。
1、表名的确定。大部分还是跟业务涉及的实体对应。
2、字段名称要符合规范。复数字段对应的字段名称必须是复数。
3、对一些不太会进行修改的引用字段可以考虑内嵌一些常用的冗余属性。比如说商品表、标签表。商品表中有一个字段tags。那么可以考虑将tags定义成如下所示的结构,因为业务上对标签显示最多的只有对其名称的显示。
1
2
3
4
tags:[{
_id: { type: 'ObjectId', ref: 'Tag' },
name: String,
}], // 标签
4、功能性一致的字段,用一个对象进行内嵌,而非水平的展开结构。比如说一张表有许多统计字段,可以将这些字段统一规整到statistics字段下。
CURD 简诉
其查询语法跟 MySQL 的 SQL 是存在很大区别的。个人在刚刚开始写的时候感觉很难记。其实它的查询语法异常简单。后面会想起来感觉所接触到的几个非关系型数据库都是这个套路,即查询语句中的条件跟存储的数据的数据结构高度相关。
举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
documents:
[
{
name:'want',
age:23,
hobby:['chang', 'tiao', 'rap', 'lanqiu'],
},
{
name:'haixing',
age:23,
hobby:['game', 'eat', 'study', 'acm'],
},
{
name:'xuejun',
age:23,
hobby:['reading', 'study'],
},
{
name:'xidada',
age:23,
hobby:['reading', 'game'],
}
]
查询的时候比方说要查年龄大于 22 并且喜欢的学习(study)的人。
1
2
3
4
5
6
db.getCollection.user.find({})。find中的{}就是我们要匹配的文档。
那么我们将条件进行填充即可。
{
age:{ $gt:22},
hobby:'study' //因为hobby是数组,也可以这么限定:hobby:{$in:['study']}
}
查询条件默认是&&的逻辑,如果想用或的逻辑使用 $or 挂到查询对象上。
1
2
3
4
5
6
{
$or: [{ age: { $gt: 20 }, age: { $lt: 10 } }],
hobby:'study'
}
等同与MySQL中的 where hobby = 'study' and (age > 20 or age < 10);
mongoose
mongoose是一个主流操作MongoDB的node模块。mongoose官方文档
mongoose为模型提供了一种直接的,基于scheme结构去定义你的数据模型。它内置数据验证, 查询构建,业务逻辑钩子等,开箱即用。
整理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1. mongoose的find不同于aggregate方法。前者会自动将一个是ObjectId的字符串转为ObjectId,亦或是将一个moment对象转为Date类型,后者则需要手动的去转换。
2. 理解aggregate。这个应该算是MongoDB的东西。官方文档上有这么一段话:The aggregation pipeline is a framework for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results.翻译过来就是:聚合管道是基于数据处理管道概念建模的数据聚合框架。 文档进入多阶段流水线,该流水线将文档转换为汇总结果。
个人理解:aggregate就是对指定数据(满足$match条件)串行的执行其中定义的操作的过程。aggregate的参数是一个数组,结合文档所说其实每一个元素就是一个阶段,每个阶段我们可以对上阶段处理完的数据进行本阶段定义好的方式去加工数据。
3.populate方法,多层填充。例子:
const user = await models.User
.findOne({
_id: args.id
})
.populate('children')
.populate({
path: 'children',
populate: {
path: 'avatar'
}
});
//填充children后再针对children的avatar再进行填充。
索引的问题
由于索引是存储在内存(RAM)中,你应该确保该索引的大小不超过内存的限制。 如果索引的大小大于内存的限制,MongoDB 会删除一些索引,这将导致性能下降。
检测是否使用索引(官方文档上写了三种方式):explain()
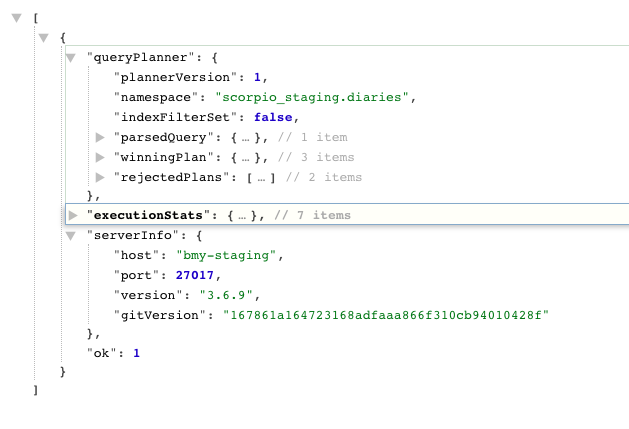
查询计划解读MongoDB官方文档传送门:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- queryplanner: 详细的说明了查询优化器选择的计划,queryplanner模式下并不会真正的执行query语句查询,而是针对query语句进行执行计划分析选出winning plan。
- namespace: query所查询的表
- indexFilterSet: 这个查询是否应用了索引过滤器。(看query有没有用索引不能看这个)
- winningplan: 查询优化器针对这次query所返回的最优执行计划的详细内容
- stage: 最优执行计划的stage有以下几个类型:
- COLLSCAN: 全表扫描
- IXSCAN: 索引扫描
- FETCH: 根据索引去检索制定文档
- SHARD_MERGE: 将各个分片返回数据进行merge
- filter: 过滤条件
- inputStage:
- keyPattern:
- indexName: winning plan所选用的index
- isMultiKey: 是否是
- direction: 查询顺序
- rejectedPlans: 其他非最优执行计划
- executionStats
- executionSuccess: 是否执行成功
- nReturned: 返回的数据条数
- executionTimeMillis: 执行时间(越少越好)
- totalKeysExamined: 索引扫描次数
- totalDocsExamined: 文档扫描次数
- executionStages
- ...
索引的最大范围:
- 1、集合中索引不能超过 64 个
- 2、索引名的长度不能超过 128 个字符
- 3、一个复合索引最多可以有 31 个字段
刚刚开始建 schema 的时候没必要过多的索引的,后面有需要再建索引。至于出现索引数据过大的情况,可以使用stats()方法进行协助查看各个索引的存储占用情况,针对不必要的索引进行清理即可。
mongoose创建索引:
1
2
3
//_id自带索引
model.index({ field : 1 }); // 1为指定按升序创建索引,-1为降序创建索引。
model.index({ field : 1, fieldB : -1 });//多字段索引
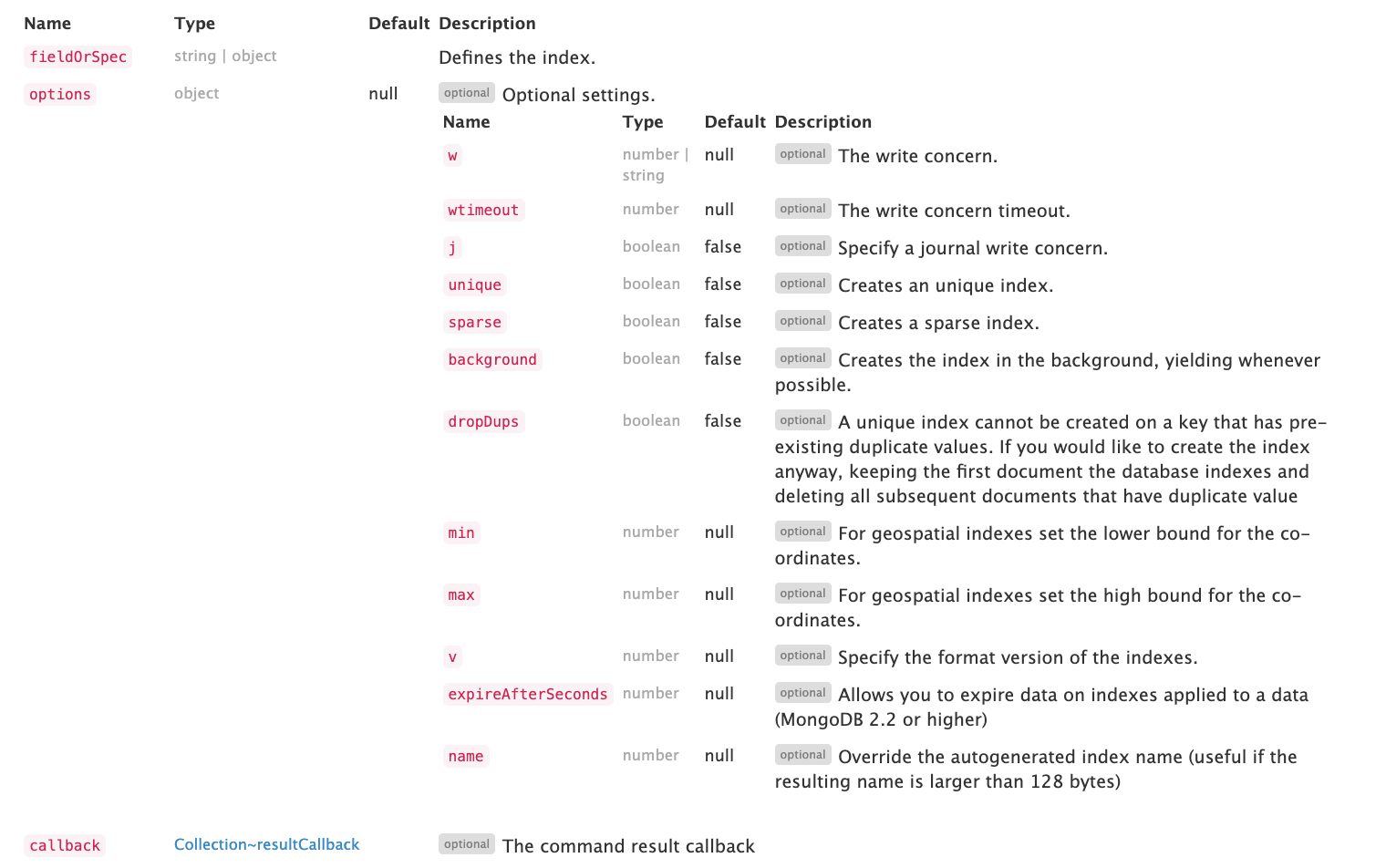
可选参数列表:
关联表
通过3.2版本的新功能$lookup来进行。
语法:
1
2
3
4
5
6
7
8
9
10
{
$lookup:
{
from: <collection to join>, //指定要执行联结的集合
localField: <field from the input documents>, //
foreignField: <field from the documents of the "from" collection>, //指定from文档中的字段
as: <output array field> //指定要添加到输入文档中的新数组字段的名称。
}
}
例子:
1
2
3
4
5
6
7
8
const res = await models.Xxx.aggregate([
{ $match: query },
{ $group: { _id: '$tags' } },
{ $lookup: { from: 'tags', localField: '_id', foreignField: '_id', as: 'tags' } },
// 关联后再做筛选
{ $match: { 'tags.name': { $all: tags_arr } } },
{ $project: { _id: 1 } },
]);
如果你使用的ORM的包是mongoose的话,请使用Query的populate方法。相关使用详情参阅:文档
正则表达式
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
MongoDB使用PCRE (Perl Compatible Regular Expression) 作为正则表达式语言。
不同于全文检索(2.6 版本以后需要开启相关配置:db.adminCommand({setParameter:true,textSearchEnabled:true})),我们使用正则表达式不需要做任何配置。
使用:
1
2
3
4
5
6
7
8
9
db.collection.find({post_text:{$regex:"xxx"}})
或者
db.collection.find({post_text:/xxx/})
//不区分大小写
db.collection.find({post_text:{$regex:"xxx",$options:"$i"}})
// 还支持在数组字段中使用正则表达式来查找内容 tags为数组字段
db.collection.find({tags:{$regex:"xxx"}})
注意:正则中使用变量。需要使用eval将组合的字符串进行转换,不能直接将字符串拼接后传入正则表达式。
1
2
let name=eval("/" + 变量值key +"/i");
title:eval("/"+title+"/i") // 等同于 title:{$regex:title,$Option:"$i"}
相关书籍
《深入学习MongDB》
1、取最值的方式:a、通过聚合然后使用一些提供的方法拿 b、[推荐使用]对某个字段进行排序然后取第一个。
2、索引一般用在返回结果总是总体数据的一小部分的时候。一旦返回的数据较大(举例:超过了集合的一半)就不要用索引了。
3、可以使用 $natural 来禁用掉索引。
4、建立分级文档加快扫描(实际用的不多感觉)。
5、AND 型查询,查询条件越苛刻(匹配最少数据量的条件)越放在前面,减少数据量。
6、OR 型查询,查询条件越宽泛(匹配最多数据量的条件)越放在前面。
7、在collection在256G之前进行分片
后记
MongoDB和关系型数据库的核心区别
核心区别就是:文档模型。
关系模型需要我们把一个数据对象拆分成许多个单项。然后存到各个相应的表中,需要的时候通过查询将所需要的数据从各个表中查询出来。
MongoDB的文档模式。文档模式存储单位是一个文档,可以支持数组和嵌套文档。在MongoDB中利用富文档的性质,很多时候,关联是一个伪需求,可以通过合理建模来避免。
文档模型的优点:
1、效率高。文档模型将数据集中到来一起,在普通机械盘中不需要在额外的移动磁头。
2、可扩展性强。如果不考虑关联,数据分区分库,水平扩展简单。
3、动态模式。文档模型支持可变数据模式,不要求每个文档都要有一样的数据结构,对很多异构数据场景支持较好。
4、模型自然。最为接近对象模型。
文档模式设计的基本策略:
一般先考虑内嵌,一般的一对一、一对多关系都可以放在一个文档中使用内嵌进行解决。
实在不行使用引用,即在主表中存储一个ID值指向另一张表的的ID值,从性能上来说我们一般需要两次以上的查询才能把相关的数据取到。
更加重要的是MongoDB暂时还不支持跨表的事务,所以对强事务场景需要谨慎使用。(4.0版本发布后MongoDB支持原生的事务操作)